Como bien sabemos de diferentes ámbitos, es difícil encontrar una solución única para todos los problemas y esto no es diferente con las TIC y, más concretamente en IoT. Esta entrada del blog no pretende dar por lo tanto, una solución única a todos los problemas que nos podemos encontrar a la hora de realizar tanto procesamiento como almacenamiento de datos recogidos por sensores. Nuestro objetivo es mucho menos ambicioso, y tan solo pretendemos que esta entrada sirva como reflexión sobre las diferentes alternativas que están disponibles hoy día, tanto para el tratamiento y procesamiento de datos recogidos por sensores, como para el almacenamiento de estos.
En esta entrada discutiremos ventajas e inconvenientes sobre diferentes lugares en donde se pueden procesar y almacenar estos datos e intentaremos con ello dar a entender por qué la alternativa que proponemos en nuestro proyecto StoreOnMe nos parece la más acertada para la problemática que intentamos abordar. Ya que es un tema largo y con muchos detalles, hemos decidido dividir en dos partes esta entrada. En esta primera parte revisaremos las ventajas e inconvenientes de los entornos de Cloud Computing para el sector agrícola, siendo en la siguiente entrada cuando nos centraremos en las alternativas para solventar los problemas que comentaremos.
Revisaremos en esta entrada, como hicimos en la anterior, el sector agrícola desde cuatro de sus piezas fundamentales. El primero, el de la explotación agrícola, el campo, incluso el de la propia planta. En segundo lugar, el de los medios y maquinaria usados para la manipulación del fruto en el campo. En tercer lugar, desde el punto de vista del sector industrial agrícola, que se ocupa del tratamiento y procesamiento de los alimentos, tanto para su selección como para su empaquetado, entre otros. Por último, desde el punto de vista de los medios logísticos que se ocupan de su transporte. Nuevamente, podríamos discutir si considerar a todas estas piezas parte del sector agrícola, pero sin todas ellas sería difícil tener una visión global del sector y del producto desde que se prepara el campo para el sembrado hasta que el producto llega al consumidor final. Como veremos en esta entrada, la trazabilidad jugará un papel fundamental.
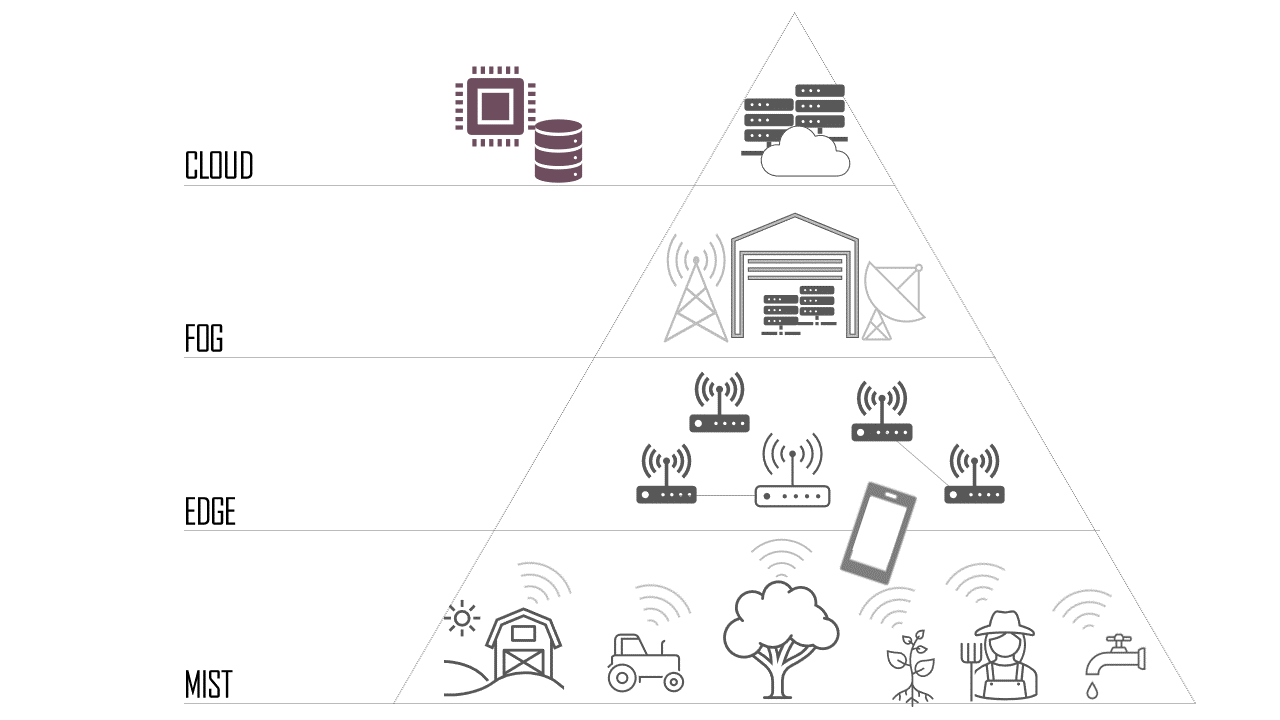
Por no dilatar más la cuestión vamos allá con nuestra revisión (subjetiva) sobre la computación y almacenamiento en Cloud, Fog, Edge y Mist en el sector agrícola. Presentemos estos términos primero para separarlos claramente, pues incluso la bibliografía no es clara en la separación de algunos de ellos, en especial al diferenciar entre Edge y Mist.
Cloud Computing
Cloud Computing es de los cuatro, el término más claro para todo el conocedor de las TIC. Su traducción más directa a nuestro idioma sería Computación en la Nube y podemos verla como una abstracción de la Computación tradicional, donde nosotros tenemos un computador físico que realiza el procesamiento y almacenamiento de la información. En esta abstracción, no percibimos el sistema físico, sino que queda disperso en la nube (Internet) sin tener nosotros un completo conocimiento de la máquina física que lo ejecuta. Aquí entran términos interesantes, como virtualización, etc. y uno que nos interesa especialmente en este artículo, servicio. Cloud Computing permite el procesamiento y almacenamiento de datos en Internet, en servidores físicos o virtuales de los que generalmente no conocemos la localización exacta ni el hardware que lo conforma. De hecho, este tipo de computación ha servido para popularizar los términos de Software como Servicio (Software as a Service – SaaS), Plataforma como Servicio (Platform as a Service – PaaS) e Infraestructura como Servicio (Infrastructure as a Service – IaaS).
El primero de ellos, SaaS, permite p.ej., acceder a funcionalidades software sin instalación ni procesamiento local. Pensemos por ejemplo, en un complejo algoritmo que conlleva una gran necesidad computacional por la gran cantidad de datos de entrada que tiene para calcular la previsión de granizo en la zona que ocupa una explotación agrícola. Estos cálculos serían sumamente costosos en tiempo, quizás no pudiéndose obtener una previsión fiable hasta que ya fuese demasiado tarde para tomar medidas de protección para los cultivos. Sin embargo, esta computación puede llevarse a cabo a tiempo en grandes computadores remotos, en la nube, que nosotros simplemente consultamos desde un navegador web o de manera automática desde otra máquina p.ej., un software de ayuda a la toma de decisiones.
El segundo de ellos, PaaS, permite ofrecer sobre los computadores en la nube un mayor nivel de control. Esta capa si es ya especialmente relevante para los objetivos de StoreOnMe y cualquier otro proyecto orientado al almacenamiento de información, pues es PaaS el nivel de servicio que permite controlar servicios transversales, como la comunicación o el almacenamiento dentro de un sistema remoto en la nube, algo que quedaba fuera de alcance con el modelo de servicio anterior.
Por último, IaaS, es el nivel de servicio que proporciona control sobre lo más cercano al hardware (físico o virtual) de las máquinas remotas. De hecho, a este nivel se le conoce también como Hardware como Servicio. Este nivel es, sin duda, el de mayor relevancia para StoreOnMe, pues es el que proporciona mayor control sobre el almacenamiento de datos remoto, aunque también sobre capacidades computacionales.
Los conceptos de SaaS, PaaS e IaaS se han popularizado con Cloud Computing, aunque hoy día se han llevado a otras capas de computación más cercanas al productor de información y se han incluido especialmente en entornos Fog Computing pero también más tímidamente en entornos Edge, dentro de “nubes” propietarias. Preguntar si fue antes el huevo o la gallina, hablando en nuestro caso de computación remota y la orientación a servicios es algo difícil de contestar. En cualquier caso, debe quedar claro que este tipo de orientación a servicios se está llevando a otros niveles, aunque nosotros no los incluiremos a continuación por evitar ser repetitivos.
Cloud Computing juega un papel fundamental dentro del sector agrícola ya y creemos que cada vez lo hará más por el propio aumento de empresas interesadas en sistemas que no conlleven grandes desembolsos iniciales. Una de sus principales ventajas es pues, la baja inversión inicial, pero también la baja complejidad que conlleva su puesta en producción. Esto posibilita el rápido despliegue de soluciones, de modo que podemos tener sistemas en funcionamiento rápidamente. Por último, una de sus mayores ventajas es la escalabilidad. Puede que inicialmente nuestro sistema sea más simple y lo queramos ir haciendo crecer con el tiempo, o que el sistema tenga que soportar pocos clientes inicialmente y, que vayamos ampliando cuota de mercado con el tiempo, etc. y a todas estas necesidades crecientes o decrecientes se adapta perfectamente la computación en la nube.
Tanto si pensamos en cualquier tipo de empresa, incluida una explotación agrícola que está comenzando, como en una que quiere probar si el uso de la sensorización de sus cultivos y/o de la propia explotación, Cloud Computing parece un medio ideal para ellos para evaluar las ventajas que le puede suponer esta digitalización.
Pensando en los medios y maquinarias agrícolas, Cloud Computing también parece una solución ideal para diferentes aspectos. Por ejemplo, si pensamos en los turismos actuales, muchos de ellos hacen conexiones con las nubes de sus fabricantes y esto no es diferente en los vehículos industriales agrícolas, que ya pueden enviar reportes a sus fabricantes sobre fallos en los sistemas, necesidad de actualizaciones del firmware de control, etc. Esto abre toda una nueva maraña de posibilidades comerciales para ellos, pues sabes cuándo necesitamos hacer la revisión de un tractor o cosechadora y pueden casar esa necesidad/demanda con la oferta que ofrecen sus concesionarios. Si el uso de estos servicios requiere algún tipo de subscripción o pago recurrente, el sistema resulta rentable para el fabricante de maquinaria, pues pese a que cada vez necesitará mayores recursos para computar y almacenar los datos del creciente número de vehículos que irá vendiendo, los ingresos también crecerán en consonancia, con lo que no tendrá problemas en este sentido.
Respecto al uso de Cloud Computing en industrias agrícolas orientadas al procesamiento y empaquetamiento de cultivos, estas industrias no tienen, como ya comentábamos en nuestra anterior entrada en este blog, un reto centrado en la sensorización, que ya han alcanzado de manera generalizada. El reto en este sector es otro, principalmente para que los sensores sirvan, entre otros, para casar oferta y demanda. De este modo se permitirá adecuar la producción tanto al estado de los cultivos como a las necesidades de mercado sobre estos.
Por último, respecto al sector logístico relacionado con la agricultura, este se enfrenta principalmente a retos que tienen que ver con el estado y conservación de los cultivos durante su transporte y distribución. Por un lado, lo vehículos en sí pueden beneficiarse de Cloud Computing en la misma medida que ya hemos comentado para la maquinaria industrial. Por otro lado, veremos que la sensorización del producto, embalaje o contenedor va ganando auge. Ya es habitual en algunos subsectores logísticos, aunque no tanto en el agrícola, la identificación automática de productos, que permite una automatización y contenido rápido en el intercambio de productos entre puertos secos, almacenes mayoristas y minoristas hasta llegar al proveedor final. Entre las tecnologías más usadas destacan el uso de RFID y similares para la identificación de productos y GPS para su localización, aunque esta última, por su precio, suele destinarse al seguimiento de producto de alto valor, algo que, a los precios actuales, queda fuera del uso actual masivo en productos agrícolas.
Para todas las industrias alrededor de los cultivos, en concreto las cuatro citadas anteriormente, hay un concepto transversal a todas ellas: la trazabilidad del alimento. Esta trazabilidad es hoy día limitada, pero en el futuro veremos que cada vez se enriquecerá más con datos tomados en diferentes fases del cultivo y su entorno (la tierra, la atmósfera, etc.). Esto permitirá asegurar que p.ej., en un producto etiquetado como ecológico no se han usado ciertos productos fitosanitarios, pues modificarían los valores entre otros de pH del terreno sensorizado. Para que esto sea posible, Cloud Computing jugará un papel fundamental junto con tecnologías incipientes como blockchain, que permitan crear una trazabilidad inalterable sobre los productos. Esto permitiría asegurar desde el lugar y medios de producción usados para su crecimiento, como los medios usados para su distribución, si se ha alterado una posible cadena de frío, etc. Esto implica que los diferentes sectores usen un medio común de comunicación, procesamiento y almacenamiento de datos y la única respuesta actual a este reto es blockchain.
Pese a que podríamos ver Cloud Computing como una tecnología ideal, su uso conlleva ciertos problemas que detallaremos a continuación. Pese a que las situaciones son muy diversas y nos podemos encontrar con empresas en muy diferentes situaciones tecnológicas: empresas con experiencia, sin experiencia, con hardware propio, etc. Nosotros aquí reflejamos los problemas más habituales y genéricos al trabajar Cloud Computing y unos u otros afectarán a los diferentes sectores relacionados con el sector industrial que hemos detallado anteriormente. Destacamos en este sentido los siguientes problemas:
- Hardware ya adquirido para sensorizar del que estamos desaprovechando sus inherentes capacidades de computación y/o almacenamiento (sensores, e infraestructura como hubs y routers para comunicar los sensores y actuadores principalmente)
- Pérdida de privacidad, pues al almacenar los datos en servidores externos podemos incluso tener problemas al no cumplir la legislación vigente sobre protección de datos, que si bien no afectarían al cultivo, si podrían tener connotaciones legales cuando almacenamos información de trabajadores p.ej., para geolocalizarles para evitar accidentes con medios autónomos dentro de la explotación o para medir sus constantes vitales para ver si les ha ocurrido algo mientras realizan labores manuales, muchas veces en condiciones de calor.
- Pérdida de control sobre los datos, en la que al usar medios hardware de terceros, estos conllevan el procesamiento y almacenamiento en su propia infraestructura y nos deja sin acceso a los datos históricos cuando dejamos de usar su hardware, etc. Esto crea dependencias en el tiempo que son importantes tener en cuenta.
- Pérdida de ajustes sobre la QoS, incluida la seguridad que ya hemos discutido, pero también de aumento de la latencia. Este parámetro de calidad de servicio es muy relevante en aplicaciones donde que la comunicación no se retrase es crítico. Si bien esto no es relevante para muchos cultivos, si lo es en los medios usados para el mantenimiento de estos, que pueden incluir sistemas de conducción autónoma, entre otros.
- Aumento de coste a largo plazo, siendo este uno de los problemas que el sector agrícola se va a encontrar tras las primeras prospecciones en la sensorización. Esto es algo que la industria agrícola ya ha vivido, pero que en los entornos que todavía no han alcanzado este nivel tecnológico está todavía por llegar. Esto tiene mucho que ver con la solución proporcionada con StoreOnMe, donde ya realizamos un estudio que puede verse publicado en https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=8819993 . En este estudio se observa el claro aumento de precio en el tiempo que conlleva el uso de infraestructuras Cloud, pues día a día tenemos que pagar no solo por el consumo de transferencia de datos y almacenamiento del día actual, sino también por todos los datos que tenemos almacenados en sus servicios de día anteriores.
- Aumento de consumo energético (comunicaciones, procesadores…) que, dada la situación mundial actual, sería deseable disminuir. En este sentido, se ha estudiado que las comunicaciones en IoT con computación en la nube requieren aproximadamente 18 saltos de media en comunicaciones intercontinentales para llegar desde el productor de datos hasta un destino. Esto aumenta la latencia, como ya hemos comentado, pero además es necesario que todos esos sistemas por los que se encaminan las comunicaciones estén conectados, por lo que consumen energía continuamente. Además, al llegar al destino, el sistema de computación usado para el procesamiento y/o almacenamiento suele ser un servidor de grandes prestaciones, que requiere refrigeración especial y todo ello aumenta el consumo energético total del sistema.
Se ve claramente en base a estos problemas, que muchas de las soluciones pasan por acercar los sistemas de cómputo a los lugares donde se generan los datos. En la siguiente entrada que publicaremos en este blog veremos como Fog, Edge y Mist Computing pueden solventar parte de los problemas que hemos detallado y que están totalmente alineados con la aproximación que seguimos en el proyecto StoreOnMe.