En esta nueva entrega se resumen los avances conseguidos, por una parte, en la localización de la posición y orientación espacial de los sarmientos, paso fundamental previo a plantear cualquier sistema de corte, y por otra, en el control del manipulador que tendrá que moverse hasta los puntos que determine el sistema de visión.
Con el fin de optimizar el proceso de desarrollo, implementación y pruebas, y de contar con un escenario propicio para el prototipado rápido, se decidió que un primer paso tenía que ser modelar el sistema en 3D, para poder trabajar desde Gazebo (https://gazebosim.org/), que es un simulador para diseño, desarrollo e investigación de aplicaciones robóticas, completamente compatible con ROS, donde es posible integrar además el sensor Realsense D435i. Esta primera tarea, a la que se ha tenido que dedicar bastante tiempo, supone un paso fundamental para trabajos futuros, puesto que modificar la disposición de los elementos para distintas pruebas podrá realizarse sin apenas esfuerzos, ni económicos, ni de tiempo.
Localización espacial
Como se introdujo en la primera entrada, la localización espacial se realiza partiendo de la información obtenida de un sensor RGBD, en concreto del modelo Intel Realsense D435i (https://www.intelrealsense.com/depth-camera-d435i/), que integra, en un único dispositivo, una cámara RGB, una cámara de profundidad, además de un sensor inercial IMU y un procesador Movidius con características especiales para este tipo de aplicaciones de visión por computador.
Para obtener información relevante a partir de estos sensores se pueden plantear diferentes estrategias, como se discutió en la primera entrada. En este caso, se ha optado por una localización mediante pipeline RGB+D, que consta de un primer paso en el que el objeto se localiza mediante un detector de objetos, en nuestro caso una Red Neuronal Convolucional (CNN) (en concreto el modelo Mask R-CNN), y un segundo proceso que se centra en la nube de puntos procedente de la cámara de profundidad y cuyos puntos se encuentren dentro de la máscara obtenida en el primer paso (figura 1). Como se verá más adelante, esta identificación de puntos no resulta una tarea trivial.
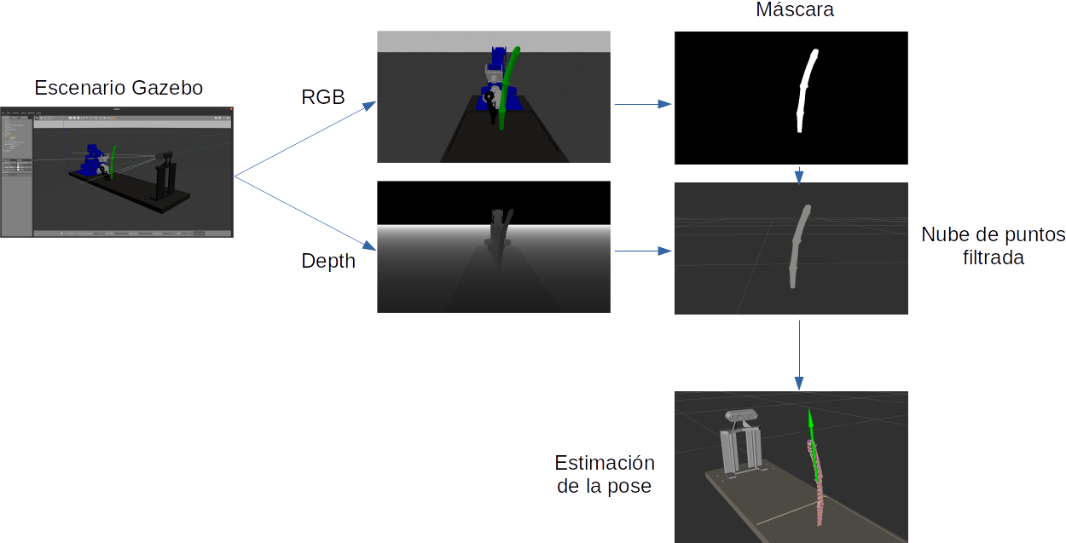
En un primer momento, es posible pensar que combinar la información RGB y la de profundidad es tan sencillo como superponer las imágenes capturadas por ambos sensores, sin embargo, esto no es así, y se debe a varias razones:
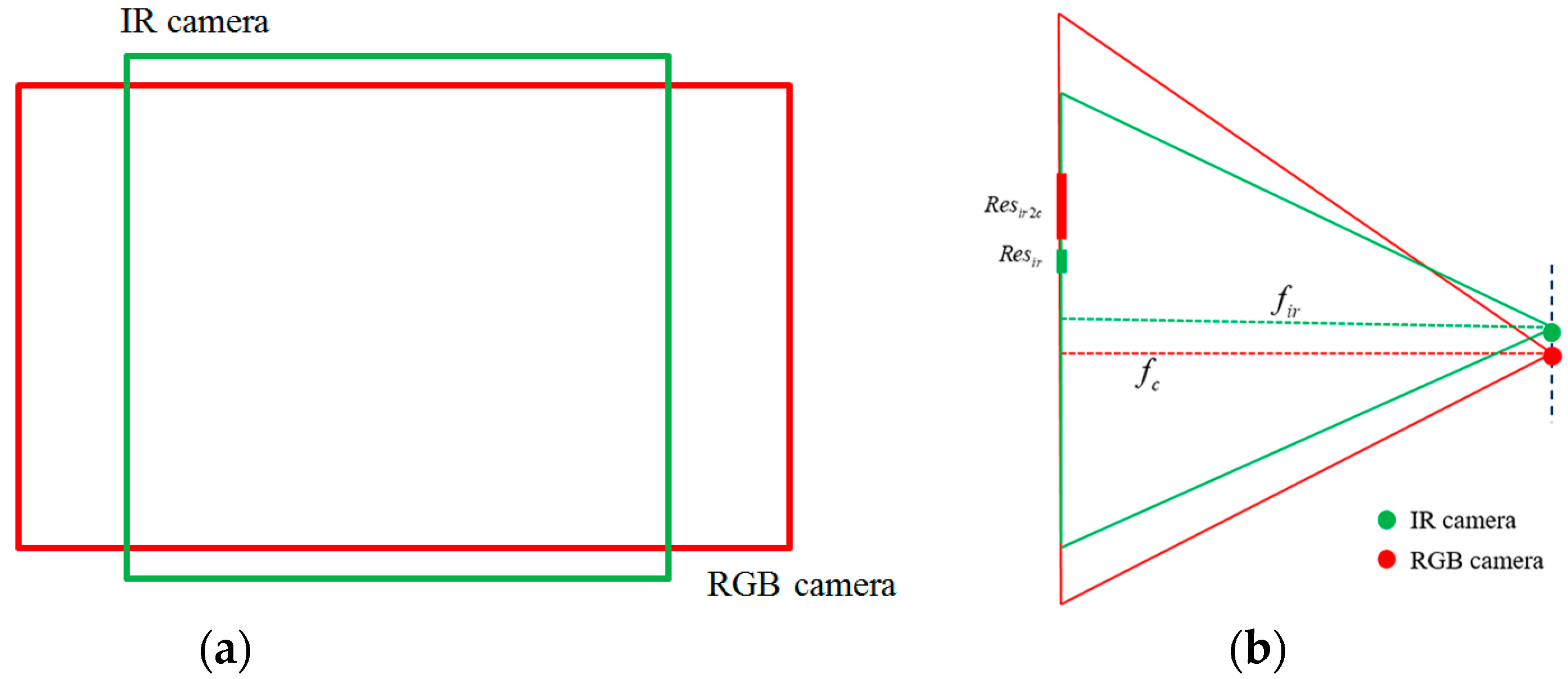
- Ambos sensores tienen resoluciones diferentes: a priori esto tendría fácil solución ampliando o recortando las imágenes, que además de una resolución diferente, también tienen una relación de aspecto diferente.
- Los dos captadores están situados en puntos espacialmente diferentes dentro del sensor, lo cual a grandes distancias del sensor no supondría un problema, pero este error de paralaje sí es notable a cortas distancias.
- El tercer y fundamental problema es que las distancias focales de ambos sensores no son iguales, lo que imposibilita definitivamente la superposición como solución a nuestro problema.
En la siguiente figura se ilustran estos problemas:
Para poder relacionar por tanto, las imágenes procedentes de los diferentes captadores, se ha de tener un conocimiento conciso de la geometría de dichos captadores. Por suerte, existen herramientas que nos permiten establecer estas características, en lo que en el ámbito de la visión por computador se conoce como modelo geométrico de la cámara, que relaciona los puntos del espacio (puntos objeto) con los puntos de la imagen (puntos imagen) mediante una transformación proyectiva que obedece a la siguiente ecuación:

donde (x,y,z) son los puntos imagen, (X,Y,Z) los punto objeto, fx, fy las distancias focales en los ejes x e y de la imagen, y cx, cy las distancias, en x e y respectivamente, desde el centro del sensor al centro de coordenadas de la imagen.
A la matriz:

se le conoce como matriz intrínseca.
Por otro lado, también es necesario introducir una serie de correcciones debidas a las imperfecciones de las lentes. Estas distorsiones pueden aproximarse mediante desarrollos en serie, donde lo habitual es quedarse con los principales coeficientes de dos deformaciones, la radial y la tangencial.
El uso de estos modelos matemáticos de cámaras es habitual en tareas de visión, y en nuestro entorno de implementación (ROS), esta información se publica, junto con las imágenes de cada captador, a través de un topic normalmente llamado “camera_info”.
De manera que en la situación inicial partimos de dos imágenes tomadas por captadores diferentes y en posiciones ligeramente separadas entre sí, una imagen RGB sobre la que se aplicará la red de detección de objetos, que nos devolverá una máscara del mismo, y otra imagen, en este caso de profundidad, a partir de la que se construye una nube de puntos de los objetos situados delante de dicha cámara y dentro de su campo de visión. Con este escenario, la idea clave es aplicar la máscara resultado de la detección de objetos (obtenida con la cámara RGB) sobre la proyección de la nube de puntos (obtenida con la cámara de profundidad), pero dicha proyección se hará mediante una transformación proyectiva en la que se utilizarán la matriz intrínseca y los coeficientes de distorsión de la cámara RGB, dicho de otro modo, se creará una proyección de los puntos objeto vistos desde la posición, y con la geometría, de la cámara RGB. Sobre esta proyección, puede aplicarse la máscara resultado de la detección de objetos sin mayor problema (figura 3).
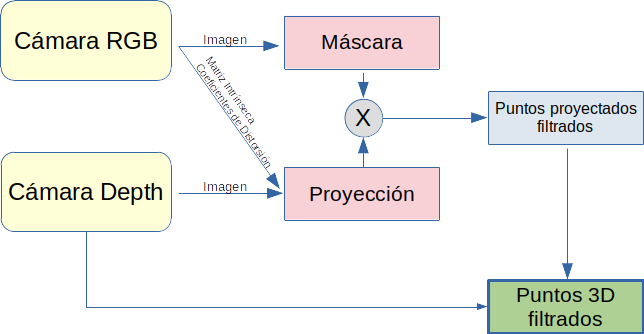
Una vez eliminados los puntos objetos cuya proyección queda fuera de la máscara de detección, es hora de determinar la localización espacial del objeto detectado (en nuestro caso el sarmiento), y para hacer esto se ha decidido tratar la nube de puntos mediante una librería específica para tal fin, la Point Cloud Library (https://pointclouds.org/), que se trata de un proyecto abierto realizado bajo licencia BSD por lo que es libre para usos comerciales y de investigación.
La Point Cloud Library (PCL) cuenta con una serie de módulos para filtrado, extracción de características, registro, segmentación… que contienen una multitud de funciones que resultan de gran utilidad para el tratamiento de nubes de puntos. Además, es compatible con ROS, lo que supone una razón de idoneidad para la justificación de su uso en este proyecto.
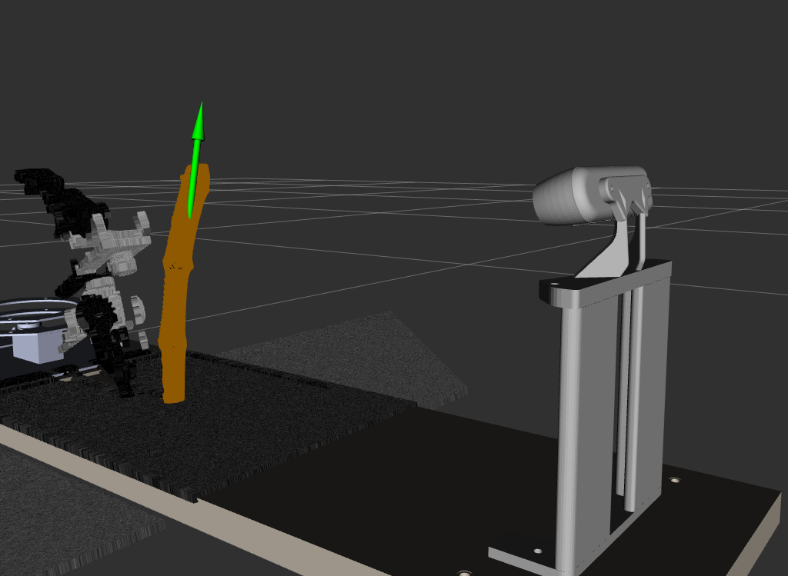
En concreto empleamos el módulo de extracción de características para obtener el centro de masas del sarmiento y su cuadro delimitador orientado (Oriented Bounding Box), y a partir de esta información construimos la pose del sarmiento, como puede verse en la figura 4.
Con el sarmiento localizado, es momento de pasar al segundo bloque: la manipulación.
Manipulación
En el bloque anterior se determinó la localización del sarmiento respecto al sistema de visión, pero ahora, la manipulación se realiza mediante un brazo robótico que se encuentra en otra posición del espacio. Por suerte, esto no es ningún problema para ROS, que cuenta con un paquete (tf) que mantiene la relación entre todos los sistemas de coordenadas definidos en el sistema, relación que representa mediante una estructura en árbol. Además, también almacena estas posiciones en el tiempo, permitiendo así usar transformaciones de puntos en distintos momentos de tiempo.
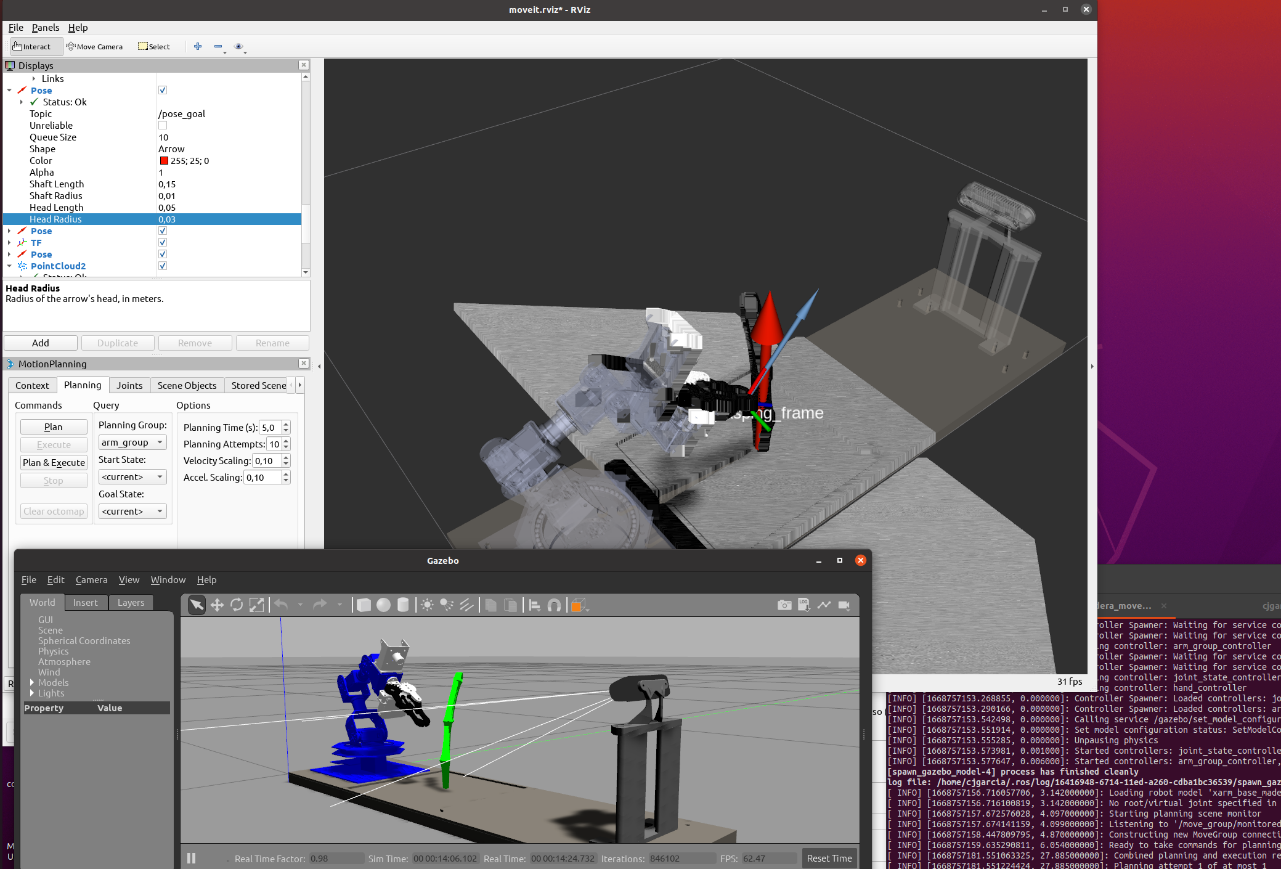
De esta manera, podemos expresar la localización del sarmiento en el sistema de coordenadas de la base del robot o incluso respecto a la garra del robot (End Effector), lo que resulta de gran utilidad puesto que será el elemento que queremos que alcance la posición del sarmiento en la orientación adecuada. Con esta relación clara, el siguiente paso es planificar la trayectoria del manipulador hasta alcanzar el sarmiento, y para ello ROS cuenta con otra gran herramienta: MoveIt (https://moveit.ros.org/).
MoveIt está formado por un conjunto de utilidades para la manipulación robótica, permitiendo tareas como planificar movimientos, calcular cinemáticas, comprobar y evitar posibles obstáculos. En la figura 5 podemos ver la integración de MoveIt y el sistema de visión simulado en Gazebo.
Un primer paso fundamental a la hora de afrontar un proyecto de robótica, y en general en cualquier aplicación de control, es el modelado del sistema. Moveit proporciona una herramienta para el modelado cinemático del brazo robótico, donde es posible definir las articulaciones, los distintos eslabones de la cadena cinemática, así como posibles ligaduras entre articulaciones. También es muy importante en este paso establecer los límites articulares con el fin de que Moveit no planifique rutas que exijan configuraciones articulares imposibles en la práctica.
En este punto, resulta importante considerar qué tipo de manipulador ha sido empleado para esta parte del proyecto. Hasta la fecha disponemos de un LewanSoul xArm 6DOF (https://hiwonder.hk/), que cuenta, como su nombre indica, con seis grados de libertad, aunque resulta conveniente aclarar que uno de estos grados de libertad se encuentra en el End Effector. Esta apreciación, lejos de ser trivial, es la que ha condicionado en mayor medida el desarrollo de esta última parte del proyecto. Tratemos de profundizar en este inconveniente.
Uno de los contenidos fundamentales en cualquier curso de robótica es el que trata las cinemáticas directa e inversa, siendo la primera la encargada del cálculo de las posiciones cartesianas en función de la configuración articular, y la segunda la encargada del caso contrario, la obtención de la configuración articular a partir de unas determinadas coordenadas cartesianas. Centrémonos ahora en el robot empleado para esta aplicación, que como se ha introducido, cuenta con seis articulaciones, aunque una de ellas no tiene influencia sobre la posición y orientación del robot, puesto que solo se encarga de abrir y cerrar la garra, de manera que solo cuenta con cinco articulaciones para su posicionamiento.
Es evidente, que sea cual sea la configuración articular, podemos calcular, mediante la cinemática directa, cuál es su posición y orientación en el espacio (esto es, tres coordenadas espaciales y tres orientaciones), y esto es posible debido a que el número de grados de libertad en el espacio cartesiano es igual o mayor que en el espacio articular (en concreto mayor). Pero, sin embargo, resulta imposible obtener posiciones articulares para cualquier configuración cartesiana imaginada, puesto que solo contamos con cinco ejes para ello. Teniendo en cuenta la geometría del brazo, es posible alcanzar cualquier posición dentro de su rango de trabajo, pero no con cualquier orientación.
De manera que con este manipulador no es posible, en general, alcanzar el sarmiento en el punto exacto que determine la red neuronal o, dicho de otra manera, es posible que la etapa de detección genere posiciones y orientaciones para el corte, donde será imposible que el manipulador pueda llegar.
Es por esto que se ha decidido emplear este robot para familiarizarse con MoveIt, y en concreto con la planificación de trayectorias, pero sin la pretensión de conseguir llegar a las zonas correctas de corte, etapa que será afrontada en proyectos futuros donde sea posible el uso de un manipulador de prestaciones que se adecúen en mejor medida a la de nuestras necesidades de manipulación.
Dado que a nuestro grupo de investigación CAPI (capi.unex.es) le ha sido concedido uno de los proyectos de Transición Ecológica y Digital en la convocatoria de 2021 (TED2021-131242B-100) con el título Sistema robotizado para la poda inteligente de viñedos los inconvenientes anteriores serán solventados con la adquisición de un brazo robotizado con 6 grados de libertad efectivos.
[1] Chen, C.; Yang, B.; Song, S.; Tian, M.; Li, J.; Dai, W.; Fang, L. Calibrate Multiple Consumer RGB-D Cameras for Low-Cost and Efficient 3D Indoor Mapping. Remote Sens. 2018, 10, 328. https://doi.org/10.3390/rs10020328