Finalizamos el proyecto VisualInspec, que pretende la automatización del proceso de escandallo de la aceituna verde de mesa a partir de técnicas de visión artificial y de detección de objetos en imágenes, utilizando nuestro detector de objetos para clasificar las aceitunas en diferentes clases. En esta última fase, hemos utilizado nuestro detector para realizar un escandallo real de una muestra de aceitunas en el que además de encontrar el tamaño de las aceitunas y el estado de madurez vamos a identificar aquellas aceitunas verdes que estén dañadas. La presencia de estos daños suele ser muy perjudiciales para el agricultor y éstos, pueden ser debidos a muchas causas, como daños producidos en el proceso de recolección y transporte, daños producidos por enfermedades y también daños producidos por factores meteorológicos como el granizo (ver Figura 1). Para ello, hemos creado el atributo calidad y sus clases asociadas verde, dañada, morada y cambiante. Como en las entradas anteriores hemos entrenado modelos con las 6 topologías utilizadas y hemos estimado los resultados de clasificación. Como en la entrada anterior, para clasificar bien un determinado objeto no basta con localizarlo correctamente sino también de asociarlo a su correspondiente clase.

De las 921 aceitunas que componen las imágenes del conjunto de test 461 son dañadas, 291 son verdes sanas, 104 cambiantes y 65 moradas. Los resultados de las métricas para cada una de las topologías las podemos observar en la Tabla 1.
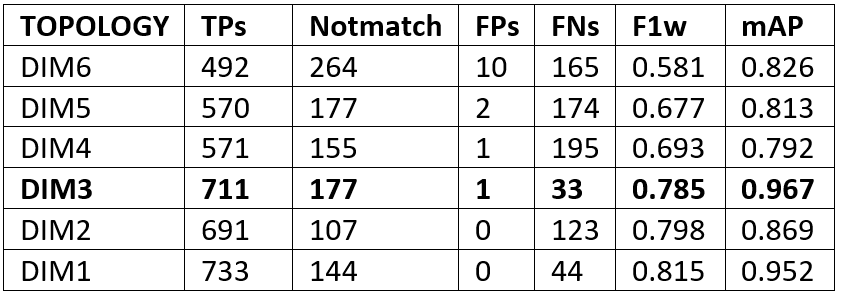
Podemos observar como la topología DIM3 obtiene unos resultados de clasificación óptimos. Finalmente, en la Tabla 2 podemos observar la matriz de confusión de la topología DIM3 y los valores de las métricas “precisión”, “recall” y f1-score separados por clase.
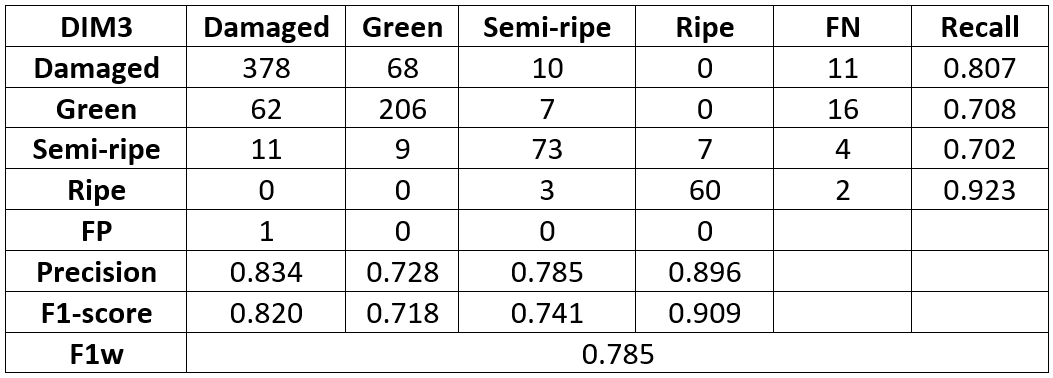
Podemos observar cómo los resultados de clasificación son bastante aceptables obteniéndose el mayor número de confusiones entre las clases verde y dañada. Como en el apartado anterior esto es debido a que incluso en la clasificación de los prototipos a veces es difícil distinguir el umbral en el que una aceituna podría ser clasificada como verde y dañada sobre todo cuando los daños son minúsculos. En la Figura 3 podemos observar la salida del clasificador de objetos con la topología DIM3 para la imagen de la Figura 2.


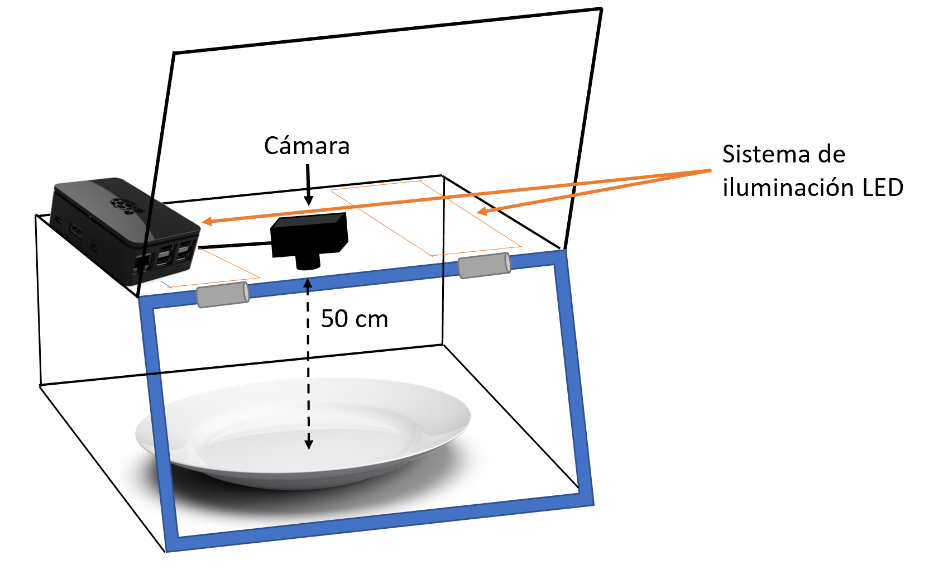
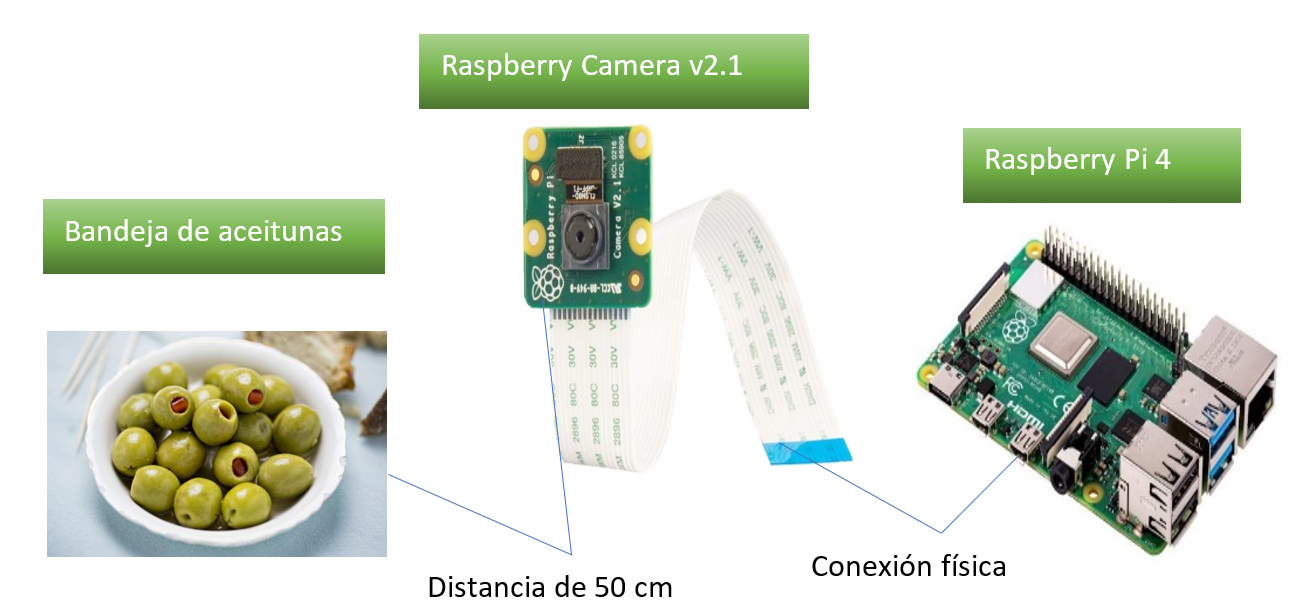
Para desplegar la solución en una empresa manufacturera, primero es necesario diseñar y fabricar una caja de captura de imágenes con el objetivo de aislar la escena de cualquier fuente de luz externa, maximizando así el control de la iluminación (ver Figura 4). El detector y clasificador final lo ejecutamos en una Raspberry Pi, un ordenador de placa única muy económico, a la que conectamos una cámara que realizará fotografías a la bandeja con la muestra de aceitunas. El uso de estos dispositivos hace que nuestro sistema pueda ser llevado a un entorno real a un precio reducido, entorno a los 73€ (50€ aproximadamente del modelo Raspberry Pi 4 de 4 GB utilizado, y unos 23€ de la cámara).
Con el objetivo de permitir que cualquier usuario con un dispositivo con acceso a Internet pueda utilizar nuestro sistema, hemos desarrollado una interfaz con Node-RED. De esta manera, tanto el servicio de Node-RED, como los ficheros que implementan el detector (descritos en Python), se encuentran en la Raspberry Pi, haciendo la función de servidor (ver Figura 5).
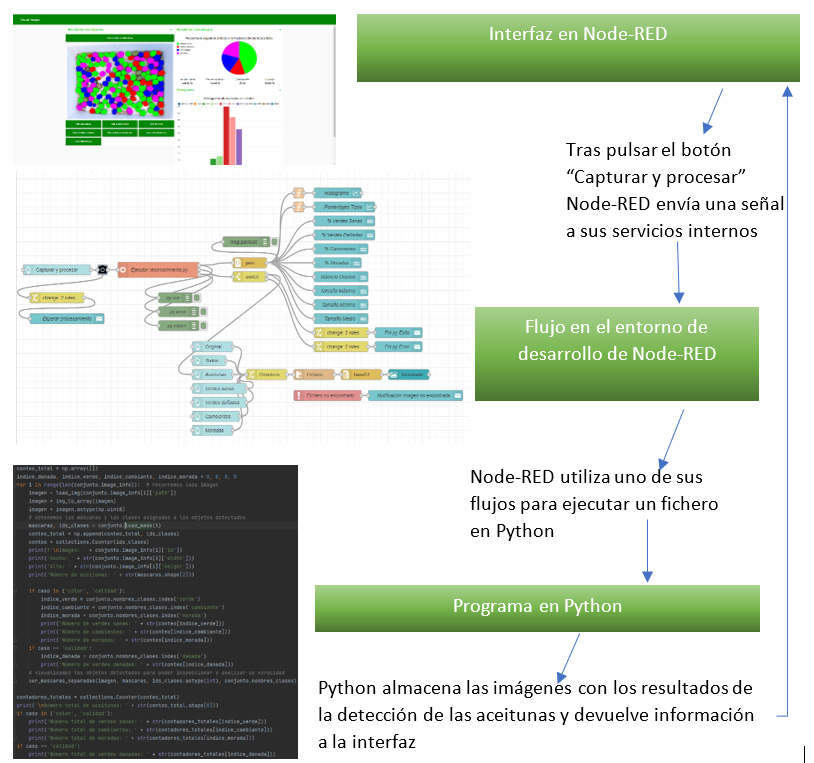
Desde la interfaz en Node-RED, el usuario podrá pulsar el botón “Capturar y Procesar”, para que la cámara realice una fotografía y comience el procesamiento de esta. Una vez clasificados los frutos los resultados se retornan a la interfaz, ejecutada en un dispositivo cliente, para que el usuario pueda continuar la interacción.
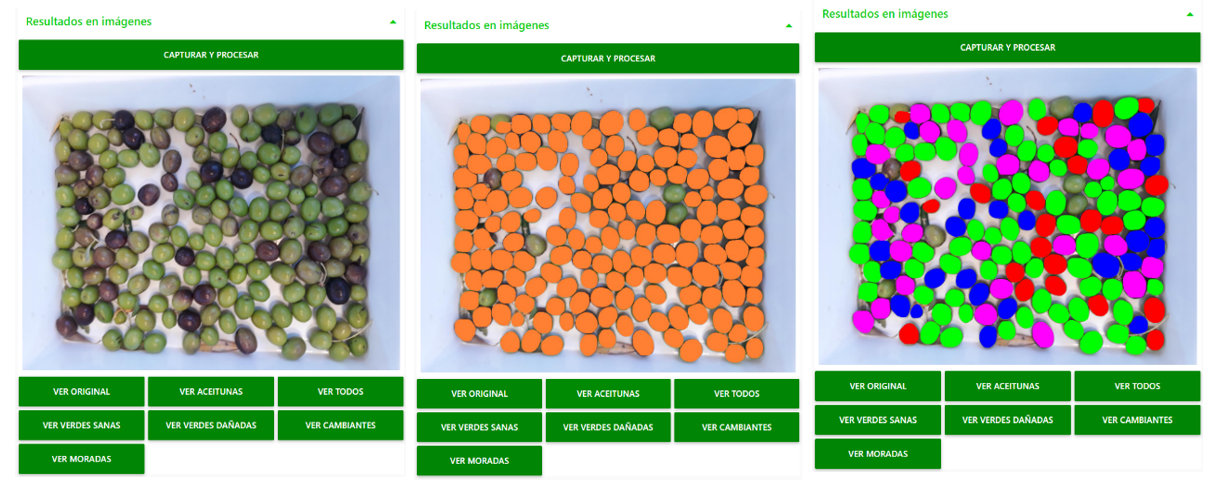
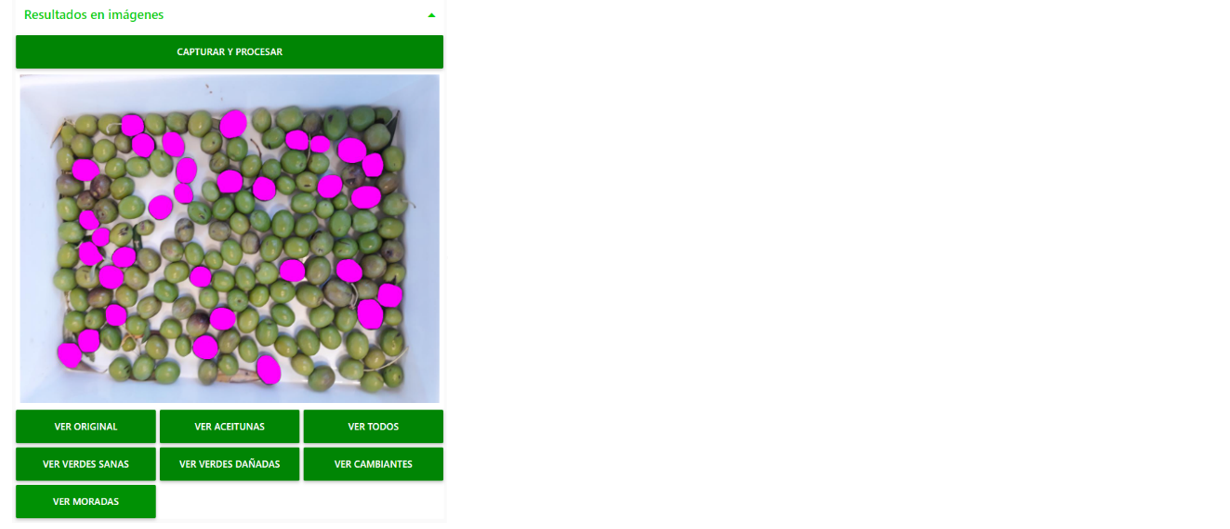
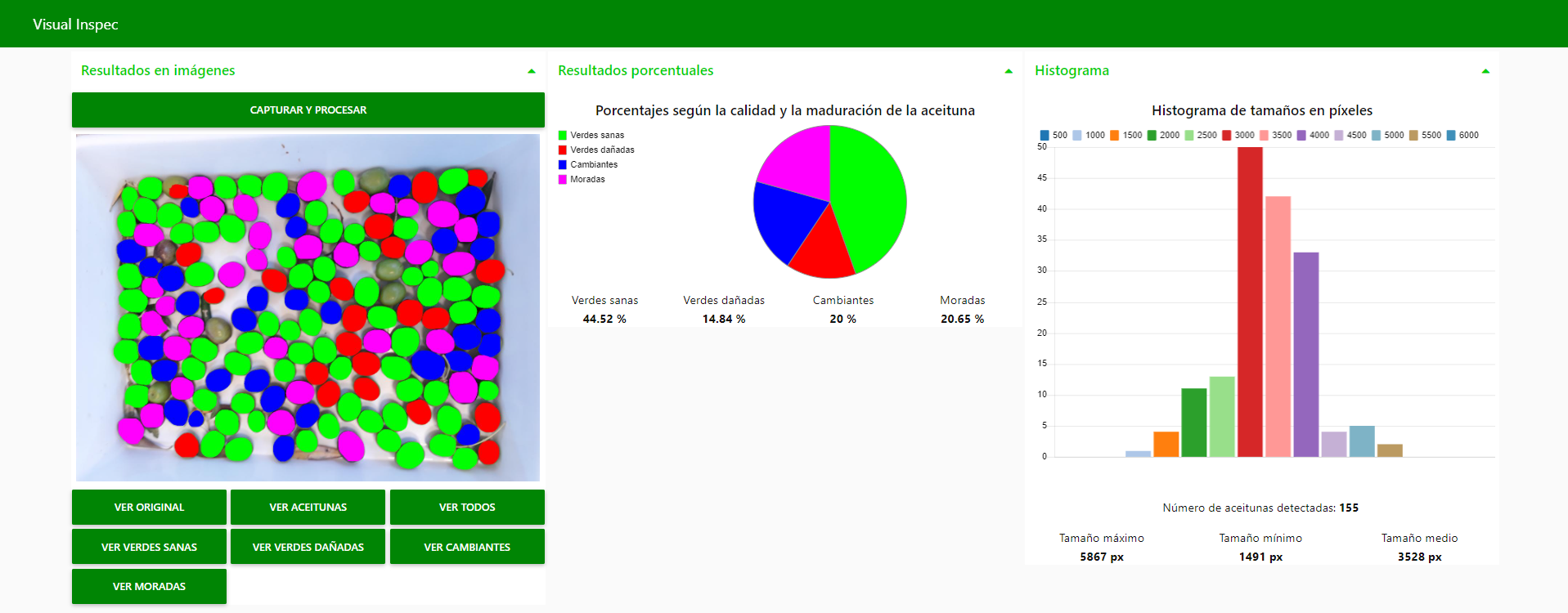
Como puede apreciarse en la Figura 6, el usuario, pulsando los diferentes botones de nuestra interfaz, podrá visualizar las diferentes imágenes resultantes de la detección y clasificación, según las aceitunas detectadas y los niveles de calidad y maduración.

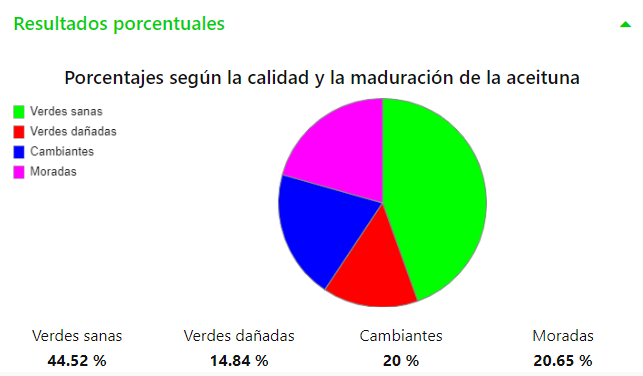
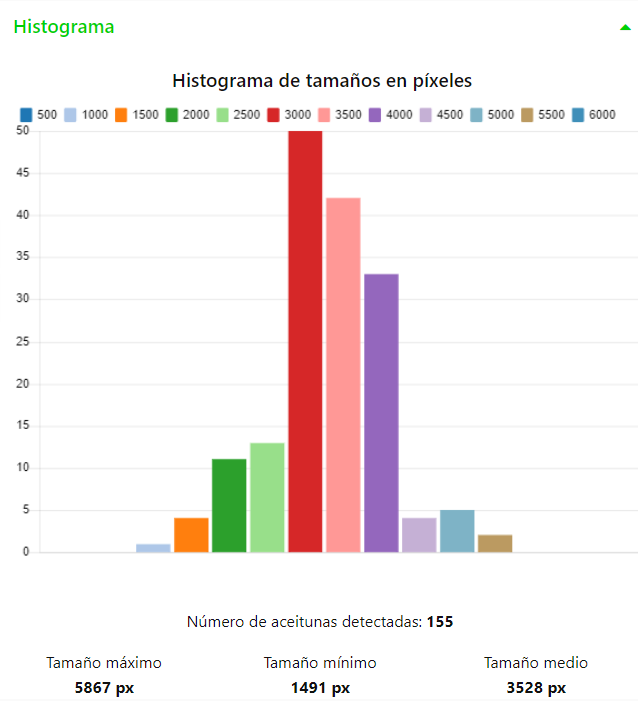
También, como resultados, se muestra un gráfico circular con los porcentajes de aceitunas según los niveles de calidad y maduración (ver Figura 7) y un histograma de los tamaños de las aceitunas expresados en píxeles (ver Figura 8).
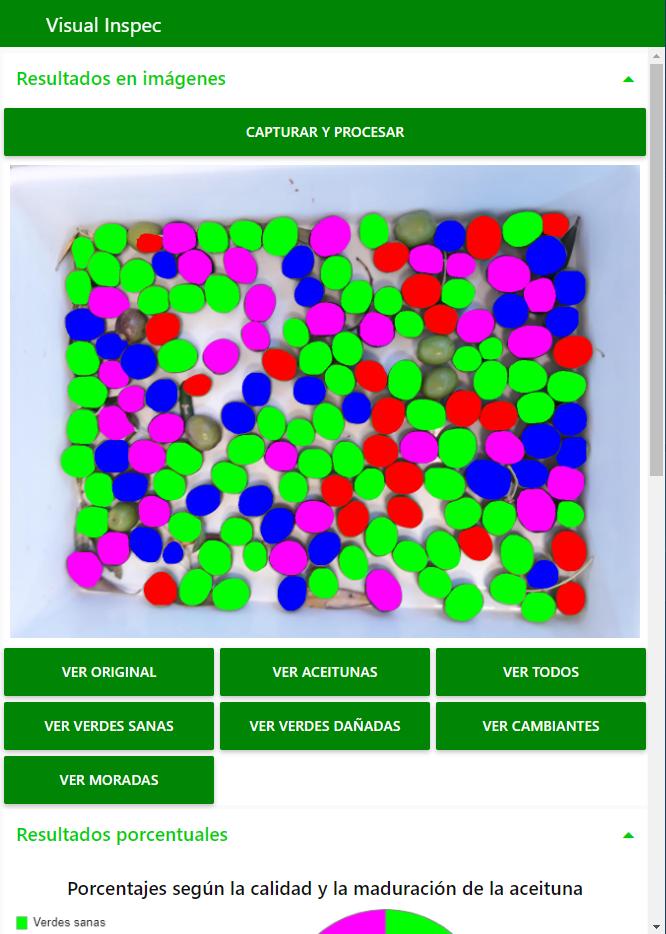
Para que el usuario pueda utilizar el dispositivo IoT que desee, tal que un ordenador portátil, una Tablet o un smartphone, los elementos que disponemos en nuestra interfaz se redistribuyen para adaptarse a la resolución de pantalla del dispositivo, como podemos ver en las Figuras 9, 10 y 11.

Conclusiones
En este proyecto hemos presentado un sistema capaz de localizar y calcular el número de aceitunas en una fotografía con mucha precisión. Como vimos en la segunda entrada del blog del proyecto (http://catedratelefonica.unex.es/avances-del-proyecto-visualinspec/) de los 921 objetos del conjunto de test fueron localizados correctamente 919 lo que nos da una precisión del 99.8%. Cuando además de localizar los objetos intentamos clasificarlos por estado de madurez (http://catedratelefonica.unex.es/visualinspec-analisis-de-resultados/) los resultados de clasificación disminuyeron a un 93.5% y cuando se incluyó la clase dañada los resultados disminuyeron a un 77.9% (porcentajes extraídos de la matriz de confusión de la Tabla 1).
Como mejora de los resultados para un trabajo futuro incluimos la posibilidad de utilizar el detector de objetos para localizar las aceitunas y un clasificador basado en aprendizaje profundo para la clasificación de las aceitunas en las categorías establecidas.