![]()
Continuamos el proyecto VisualInspec, que pretende la automatización del proceso de escandallo de la aceituna verde de mesa a partir de técnicas de visión artificial y de detección de objetos en imágenes, utilizando nuestro detector de objetos para clasificar las aceitunas en diferentes clases.
En primer lugar, hemos tratado estimar el índice de maduración de una muestra. Para ello hemos creado el atributo color y sus clases asociadas verde, morada y cambiante. Hemos entrenado modelos con las 6 topologías utilizadas en la entrada anterior referidas a las dimensiones de la imagen de entrada y los anchors, y hemos estimado los resultados de clasificación. En este caso, para clasificar bien un determinado objeto no basta con localizarlo correctamente sino también de asociarlo a su correspondiente clase. De esta forma en nuestra tabla de resultado aparecen dos nuevas columnas denominadas Match y Notmatch. Match corresponde a los objetos que han sido detectados y clasificados correctamente y Notmatch a los objetos que a pesar de haber sido detectados correctamente no han sido clasificados de manera correcta. Los valores de los falsos positivos (fp) y falsos negativos (fn) siguen teniendo el mismo sentido que en la entrada anterior.
Por otro lado hemos calculado otras métricas para evaluar el rendimiento del clasificador de objetos “precision” y “recall” y a partir de estas el “F1-score”. Además, en problemas multi-clase y especialmente cuando las clases no están balanceadas, es decir, el número de objetos presentes en los conjuntos puede ser distinto para cada clase, suele ser habitual que el cálculo de estas métricas se realice por clases y luego se haga una media ponderada para calcular el valor final, que en el caso del “f1-score” le llamaremos f1w. Finalmente, hemos calculado la eficiencia de cada uno de los modelos sobre el conjunto de test calculando el mean Average Precission o mAP.
De las 921 aceitunas que componen las imágenes del conjunto de test 755 son verdes, 101 cambiantes y 65 moradas. Los resultados de las métricas para cada una de las topologías las podemos observar en la tabla 2.
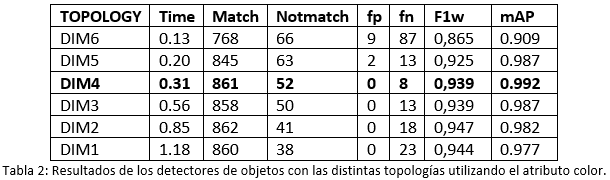
Podemos observar como la topología obtiene unos resultados de clasificación muy óptimos con unos tiempos de ejecución aproximadamente cuatro veces menor que la topología DIM1.
Finalmente, en la tabla 3 podemos observar la matriz de confusión de la topología DIM4 y los valores de las métricas “precision”, “recall” y f1-score separados por clase.
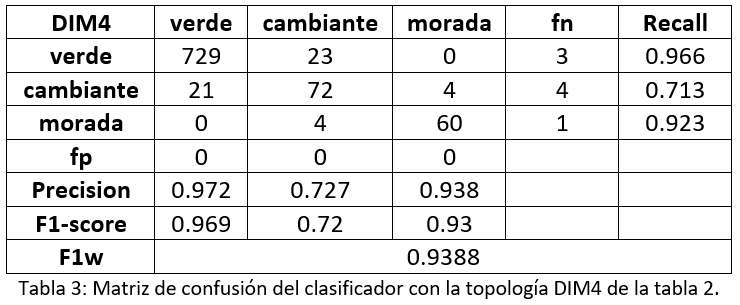
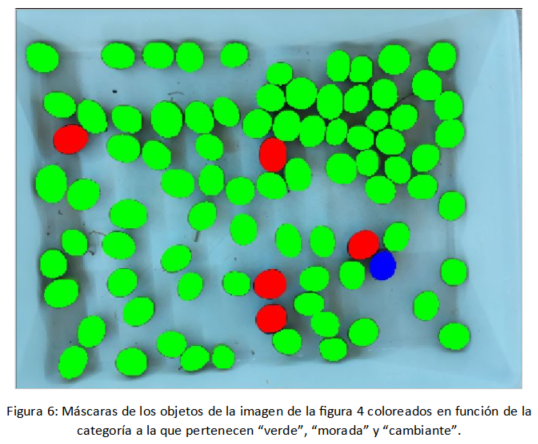
Podemos observar como los resultados de clasificación son bastante aceptables obteniéndose el mayor número de confusiones entre las clases verde y cambiante. Esto es debido a que incluso en la clasificación de los prototipos a veces es difícil distinguir el umbral en el que una aceituna podría ser clasificada como verde o cambiante. En la figura 6 podemos observar la salida del clasificador de objetos con la topología DIM4 para la imagen de la figura 4. Podemos observar cómo, en este caso, todos los objetos son detectados y clasificados de manera correcta.