Hace poco tiempo os mostrábamos los comienzos del proyecto VisualINSPEC. En esta nueva entrada conocemos cómo sigue evolucionando el proyecto.
Una vez seleccionado el Ground Truth de cada una de las imágenes entrenaremos los primeros modelos y evaluaremos la tasa de éxito. Para ello dividimos el conjunto de imágenes en un conjunto de entrenamiento (30 imágenes) y uno de test (10 imágenes).
Como el objetivo es implementar el detector de objetos en un sistema de bajo coste tipo Raspberry Pi vamos a evaluar la tasa de éxito en función de la resolución de las imágenes de entrada ya que a menor resolución menor es el tiempo de computo. En total haremos varios experimentos.
FASE 1.- Tasa de éxito a la hora de detectar los objetos y sus máscaras a distintas escalas de resolución de la imagen. Para ello creamos son el software via la atributo objeto con una única clase o id (aceituna). Una vez detectada la máscara de los objetos podemos extraer el calibre de cada uno de ellos en función del número de pixels de la máscara.
FASE 2.- Tasa de éxito a la hora de detectar el estado de maduración de las aceitunas a distintas escalas de resolución de la imagen. Para ello creamos el atributo color con tres ids o clases verde, cambiante y morada.
FASE 3.- Tasa de éxito a la hora de detectar la calidad total de una muestra, para ello hemos creado el atributo calidad con 4 clases verde, cambiante, morada y defectuosa.
Como figura de mérito para comparar las tasas de éxito de nuestro detector utilizaremos el mAP (Mean Average Precision) sobre el conjunto de test.
De todos los algoritmos de detección de objetos propuestos en la última década Faster RCNN se considera el modelo de referencia gracias a la precisión y la robustez de sus predicciones. Nosotros hemos utilizado mask_RCNN, una evolución de Faster RCNN, que es capaz de realizar una segmentación de la imagen proporcionando una máscara para cada uno de los objetos, es decir, el conjunto de pixeles que pertenecen al objeto buscado.
Concretamente, hemos utilizado un implementación de Mask R-CNN en Python 3, keras y TensorFlow (https://github.com/matterport/Mask_RCNN). Los parámetros por defecto del modelo se encuentran en el fichero config.py y para nuestras implementaciones hemos variado los siguientes:
IMAGE_MIN_DIM and IMAGE_MAX_DIM: In «square» resizing mode images are scaled up such that the small side is = IMAGE_MIN_DIM, but ensuring that the scaling doesn’t make the long side > IMAGE_MAX_DIM. Then the image is padded with zeros to make it a square so multiple images can be put in one batch. Image dimension must be divisible by 26.
BACKBONE: The model supports “resnet50” and resnet101.
RPN_ANCHOR_SCALES: Length of square anchor side in pixels
NUM_CLASSES: Number of classification classes (including background).
RPN_ANCHOR_RATIOS: Aspect ratios of anchors.
En este momento estamos finalizando la FASE1 de los experimentos con resultados sorprendentes y tasas de éxito cercanas al 100% (mAP cercano a uno).
FASE 1
En esta fase hemos entrenado distintos modelos de detectores de objetos con los siguientes parámetros de configuración:
BACKBONE = “resnet50”
RPN_ANCHOR_RATIOS = [1]
NUM_CLASSES = 1 + 1 # Ground truth + aceituna
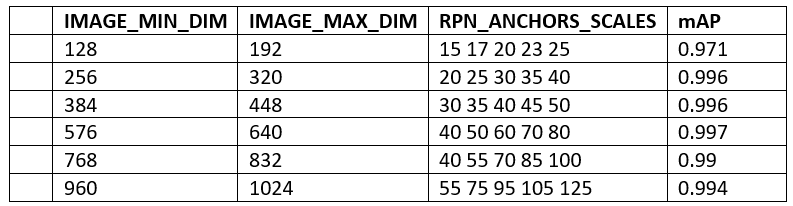
En cuanto a las dimensiones de la imagen y de los anchors hemos realizado las simulaciones que aparecen en la tabla 1 y hemos calculado la eficiencia de cada uno de los modelos sobre el conjunto de test calculando el mean Average Precission o mAP. Como podemos observar en esta fase los resultados son bastantes buenos incluso a escalas de resolución de la imagen muy bajas.
En la figura 4 podemos observar una imagen del conjunto de test y los objetos extraídos de la misma.


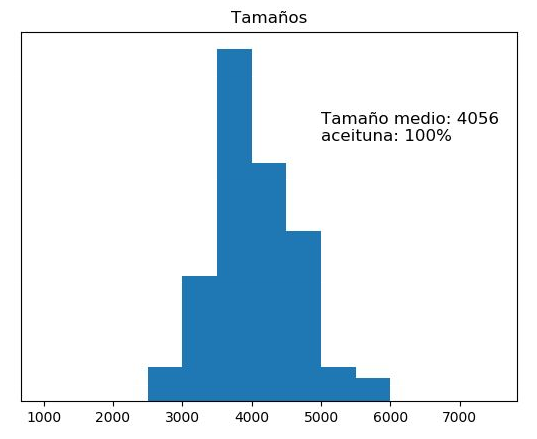
A partir de la extracción de cada una de las máscaras de los objetos es trivial encontrar una estimación del calibre de las aceitunas en función del número de pixeles que integran dicha máscara. Faltaría hacer una correlación en tiempo de campaña del tamaño real de la aceituna en función del número de pixeles en la imagen.